Observation
![]()

MetaDrive provides various kinds of sensory input, as illustrated in the next figure. For low-level sensors, RGB cameras, depth cameras, semantic camera, instance camera and Lidar can be placed anywhere in the scene with adjustable parameters such as view field and the laser number. Meanwhile, the high-level scene information including the road information and nearby vehicles’ information like velocity and heading can also be provided as the observation.
Note that MetaDrive aims at providing an efficient platform to benchmark RL research, therefore we improve the simulation efficiency at the cost of photorealistic rendering effect.
In this page, we describe the optional observation forms in current MetaDrive version and discuss how to implement new forms of observation subject to your own tasks. There are three kinds of observations we usually used for training agents:
LidarStateObservation
ImageStateObservation
TopDownObservation
By default, the observation is LidarStateObservation.
LidarStateObservation
This observation returns a state vector containing necessary information for navigation tasks. We use this state vector in almost all existing RL experiments such as the Generalization, MARL and Safe RL experiments. The state vector consist of three parts:
Ego State: current states such as the steering, heading, velocity and relative distance to boundaries, implemented in the
vehicle_statefunction of StateObservation. Please find the detailed meaning of each state dimension in the code.Navigation: the navigation information that guides the vehicle toward the destination. Concretely, MetaDrive first computes the route from the spawn point to the destination of the ego vehicle. Then a set of checkpoints are scattered across the whole route with certain intervals. When collecting navigation information, the next two or more checkpoints will be selected and their positions will be projected to the ego vehicle’s local coordinates. The final navigation observation consists of these position vectors and other information, i.e. the direction and curvature of the road. This part is implemented in the
_get_info_for_checkpointfunction of Navigation Class. Note: there are several types of navigation system can be used. Please reference Navigation section for more details.Surrounding: the surrounding information is encoded by a vector containing the Lidar-like cloud points. The data is generated by the Lidar Class. We typically use 240 lasers (single-agent) and 70 lasers (multi-agent) to scan the neighboring area with radius 50 meters. Besides, it is optional to include the information of perceived vehicles such as their positions and headings represented in the ego car’s local coordinates.
The above information is normalized to [0,1] and concatenated into a state vector by the LidarStateObservation Class and fed to the RL agents. Now let’s dive into the observation class and get you familiar with the state information collection.
ImageStateObservation

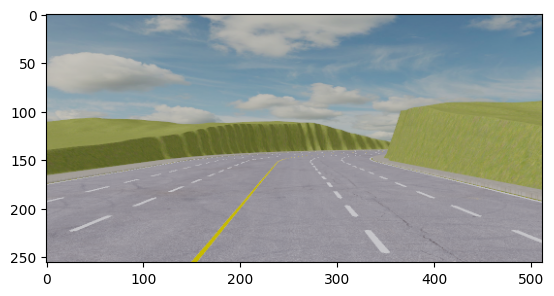
MetaDrive supports visuomotor tasks by rendering 3D scenes during the training.
The above figure shows the images captured by RGB camera (left) and depth camera (right).
By using ImageStateObservation, the image data will be returned with Ego State and Navigation for making the driving decision. In this section, we discuss how to utilize this observation.
Before using such function in your project, please make sure the offscreen rendering is working in your machine. The setup tutorial is at Install MetaDrive with headless rendering. There are two official examples using RGB camera as observation:
python -m metadrive.examples.drive_in_single_agent_env --observation rgb_camera
# options for `--camera`: rgb main semantic depth
python -m metadrive.examples.verify_image_observation --camera rgb
Concretely, to setup the vision-based observation, there are three steps:
Step 1. Set the
config["image_observation"] = Trueto tell MetaDrive maintaining a image buffer in memory even no popup window exists.Step 2. Notify the simulator what kind of sensor you are going to create in the config. A unique name should be assigned for this sensor. The image size (width and height) will be determined by the camera parameters.
Step 3. Set the
config["vehicle_config"]["image_source"]to the sensor name. Here it should bergb_camera.
An example creating RGB camera is as follows. It creates an RGBCamera with resolution=(width, height)=(128, 64). We then tell the engine to launch the image observation and retrieve the image from sensor whose id name rgb_camera. The image in the step observation dict o actually contains the images of latest several steps. Here we visualize the last image, which is the current frame. How many latest images are included in observation can be specified with config stack_size, which is 3 by default.
from metadrive.envs.metadrive_env import MetaDriveEnv
from metadrive.component.sensors.rgb_camera import RGBCamera
import cv2
from metadrive.policy.idm_policy import IDMPolicy
from IPython.display import Image
from metadrive.utils.doc_utils import generate_gif
import numpy as np
import os
sensor_size = (84, 60) if os.getenv('TEST_DOC') else (200, 100)
cfg=dict(image_observation=True,
vehicle_config=dict(image_source="rgb_camera"),
sensors={"rgb_camera": (RGBCamera, *sensor_size)},
stack_size=3,
agent_policy=IDMPolicy # drive with IDM policy
)
env=MetaDriveEnv(cfg)
frames = []
try:
env.reset()
for _ in range(1 if os.getenv('TEST_DOC') else 10000):
# simulation
o, r, d, _, _ = env.step([0,1])
# rendering, the last one is the current frame
ret=o["image"][..., -1]*255 # [0., 1.] to [0, 255]
ret=ret.astype(np.uint8)
frames.append(ret[..., ::-1])
if d:
break
generate_gif(frames if os.getenv('TEST_DOC') else frames[-300:-50])
finally:
env.close()
Image(open("demo.gif", 'rb').read(), width=512, height=256)

Besides the newly created RGBCamera, there is actually an existing one moving with the car, providing a third person perspective. It is created automatically when launching the rendering service, and captures and renders the content to the main window. Thus the buffer-size for this camera depends on window_size. Therefore, you can just use this camera rather than creating a new one. Just set the image_source=main_camera and specify the image size with window_size. Note that we set norm_pixel=True and thus the image pixel value will be unit8 and range from 0 to 255.
cfg=dict(image_observation=True,
vehicle_config=dict(image_source="main_camera"),
norm_pixel=False,
agent_policy=IDMPolicy, # drive with IDM policy
show_terrain = not os.getenv('TEST_DOC'), # test
window_size=(84, 60) if os.getenv('TEST_DOC') else (200, 100))
env=MetaDriveEnv(cfg)
frames = []
try:
env.reset()
for _ in range(1 if os.getenv('TEST_DOC') else 10000):
# simulation
o, r, d, _, _ = env.step([0,1])
# rendering, the last one is the current frame
ret=o["image"][..., -1]
frames.append(ret[..., ::-1])
if d:
break
generate_gif(frames if os.getenv('TEST_DOC') else frames[-300: -50])
finally:
env.close()
Image(open("demo.gif", 'rb').read(), width=512, height=256)

Rendering images and buffering the image observations consume both the GPU and CPU memory of your machine. Please be careful when using this. If you feel the visual data collection is slow, why not try our advanced offscreen render: Install MetaDrive with advanced offscreen rendering. After verifying your installation, set config["image_on_cuda"] = True to get 10x faster rollout efficiency! It will keep the rendered image on the GPU memory all the time for training, so please ensure your GPU has enough memory to store them.
More details of how to use sensors is at Sensors.
Using semantic camera as observation
from metadrive.envs import MetaDriveEnv
from metadrive.component.sensors.semantic_camera import SemanticCamera
import matplotlib.pyplot as plt
import os
size = (256, 128) if not os.getenv('TEST_DOC') else (16, 16) # for github CI
env = MetaDriveEnv(dict(
log_level=50, # suppress log
image_observation=True,
show_terrain=not os.getenv('TEST_DOC'),
sensors={"sementic_camera": [SemanticCamera, *size]},
vehicle_config={"image_source": "sementic_camera"},
stack_size=3,
))
obs, info = env.reset()
for _ in range(5):
obs, r, d, t, i = env.step((0, 1))
env.close()
print({k: v.shape for k, v in obs.items()}) # Image is in shape (H, W, C, num_stacks)
plt.subplot(131)
plt.imshow(obs["image"][:, :, :, 0])
plt.subplot(132)
plt.imshow(obs["image"][:, :, :, 1])
plt.subplot(133)
plt.imshow(obs["image"][:, :, :, 2])
:device(error): Error adding inotify watch on /dev/input: No such file or directory
:device(error): Error opening directory /dev/input: No such file or directory
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
Cell In[1], line 16
6 size = (256, 128) if not os.getenv('TEST_DOC') else (16, 16) # for github CI
8 env = MetaDriveEnv(dict(
9 log_level=50, # suppress log
10 image_observation=True,
(...) 14 stack_size=3,
15 ))
---> 16 obs, info = env.reset()
17 for _ in range(5):
18 obs, r, d, t, i = env.step((0, 1))
File ~/checkouts/readthedocs.org/user_builds/metadrive-simulator/envs/latest/lib/python3.11/site-packages/metadrive/envs/base_env.py:523, in BaseEnv.reset(self, seed)
521 log_level = self.config.get("log_level", logging.DEBUG if self.config.get("debug", False) else logging.INFO)
522 set_log_level(log_level)
--> 523 self.lazy_init() # it only works the first time when reset() is called to avoid the error when render
524 self._reset_global_seed(seed)
525 if self.engine is None:
File ~/checkouts/readthedocs.org/user_builds/metadrive-simulator/envs/latest/lib/python3.11/site-packages/metadrive/envs/base_env.py:415, in BaseEnv.lazy_init(self)
413 if engine_initialized():
414 return
--> 415 initialize_engine(self.config)
416 # engine setup
417 self.setup_engine()
File ~/checkouts/readthedocs.org/user_builds/metadrive-simulator/envs/latest/lib/python3.11/site-packages/metadrive/engine/engine_utils.py:38, in initialize_engine(env_global_config)
35 cls = BaseEngine
36 if cls.singleton is None:
37 # assert cls.global_config is not None, "Set global config before initialization BaseEngine"
---> 38 cls.singleton = cls(env_global_config)
39 else:
40 raise PermissionError("There should be only one BaseEngine instance in one process")
File ~/checkouts/readthedocs.org/user_builds/metadrive-simulator/envs/latest/lib/python3.11/site-packages/metadrive/engine/base_engine.py:58, in BaseEngine.__init__(self, global_config)
56 self.id_c = dict()
57 self.try_pull_asset()
---> 58 EngineCore.__init__(self, global_config)
59 Randomizable.__init__(self, self.global_random_seed)
60 self.episode_step = 0
File ~/checkouts/readthedocs.org/user_builds/metadrive-simulator/envs/latest/lib/python3.11/site-packages/metadrive/engine/core/engine_core.py:313, in EngineCore.__init__(self, global_config)
307 self.pbrpipe = init(
308 msaa_samples=4,
309 # use_hardware_skinning=True,
310 use_330=True
311 )
312 else:
--> 313 self.pbrpipe = init(
314 msaa_samples=16,
315 use_hardware_skinning=True,
316 # use_normal_maps=True,
317 use_330=False
318 )
320 self.sky_box = SkyBox(not self.global_config["show_skybox"])
321 self.sky_box.attach_to_world(self.render, self.physics_world)
File ~/checkouts/readthedocs.org/user_builds/metadrive-simulator/envs/latest/lib/python3.11/site-packages/metadrive/third_party/simplepbr/__init__.py:350, in init(**kwargs)
320 def init(**kwargs):
321 '''Initialize the PBR render pipeline
322 :param render_node: The node to attach the shader too, defaults to `base.render` if `None`
323 :type render_node: `panda3d.core.NodePath`
(...) 347 :type use_hardware_skinning: bool or None
348 '''
--> 350 return Pipeline(**kwargs)
File ~/checkouts/readthedocs.org/user_builds/metadrive-simulator/envs/latest/lib/python3.11/site-packages/metadrive/third_party/simplepbr/__init__.py:142, in Pipeline.__init__(self, render_node, window, camera_node, taskmgr, msaa_samples, max_lights, use_normal_maps, use_emission_maps, exposure, enable_fog, use_occlusion_maps, use_330, use_hardware_skinning)
139 self._recompile_pbr()
141 # Tonemapping
--> 142 self._setup_tonemapping()
144 self._shader_ready = True
File ~/checkouts/readthedocs.org/user_builds/metadrive-simulator/envs/latest/lib/python3.11/site-packages/metadrive/third_party/simplepbr/__init__.py:287, in Pipeline._setup_tonemapping(self)
281 post_frag_str = _load_shader_str('tonemap.frag', defines)
282 tonemap_shader = p3d.Shader.make(
283 p3d.Shader.SL_GLSL,
284 vertex=post_vert_str,
285 fragment=post_frag_str,
286 )
--> 287 self.tonemap_quad.set_shader(tonemap_shader)
288 self.tonemap_quad.set_shader_input('tex', scene_tex)
289 self.tonemap_quad.set_shader_input('exposure', self.exposure)
AttributeError: 'NoneType' object has no attribute 'set_shader'
TopDownObservation
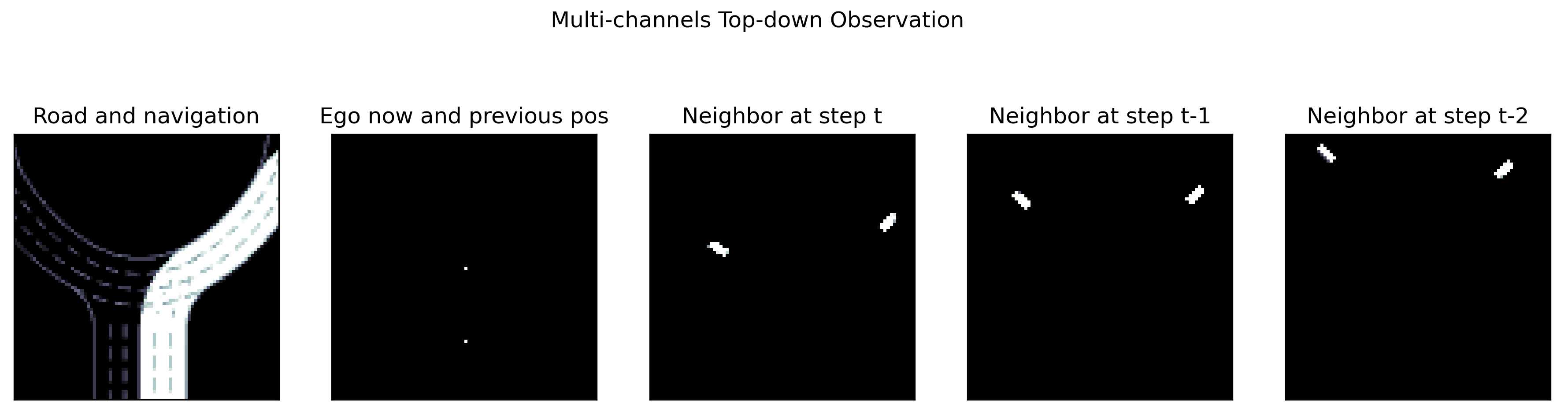
MetaDrive also supports Top-down semantic maps. We provide a handy example to illustrate the utilization of Top-down observation in top_down_metadrive.py. You can enjoy this demo via
python -m metadrive.examples.top_down_metadrive
The following is a minimal script to use Top-down observation.
The TopDownMetaDrive is a wrapper class on MetaDriveEnv which overrides observation to pygame top-down renderer.
The native observation of this setting is a numpy array with shape [84, 84, 5] and all entries fall into [0, 1].
The above figure shows the semantic meaning of each channel.
from metadrive.envs.top_down_env import TopDownMetaDrive
env = TopDownMetaDrive()
try:
o,i = env.reset()
for s in range(1, 100000):
o, r, tm, tc, info = env.step([0, 1])
env.render(mode="top_down")
if tm or tc:
break
env.reset()
finally:
env.close()
Customization-MultiSensor
We encourage users to design observations according to specific demand. For all environments, the observation of the agent is determined by the function env.get_single_observation, which is defined as follows:
from metadrive.utils.doc_utils import print_source
from metadrive.envs.metadrive_env import MetaDriveEnv
print_source(MetaDriveEnv.get_single_observation)
By default, the observation is LidarStateObservation, while image_observation=True will change it to ImageStateObservation. There are two ways to change the observation class to a customized one. The first way is creating a new environment with the get_single_observation overwritten to return your customized observation. TopDownMetaDrive is implemented in this way.
from metadrive.utils.doc_utils import print_source
from metadrive.envs.top_down_env import TopDownMetaDrive, TopDownSingleFrameMetaDriveEnv
print_source(TopDownSingleFrameMetaDriveEnv)
print_source(TopDownMetaDrive)
The second way is specifying the observation class in the field agent_observation of the config when creating the environment. The new observation class has to inherit from BaseObservation and implement the property observation_space (with @property decorator) and the function observe(). In the following example, we make a customized observation class which collects both vehicle states and images from three types of cameras.
from metadrive.envs.metadrive_env import MetaDriveEnv
from metadrive.component.sensors.rgb_camera import RGBCamera
from metadrive.component.sensors.semantic_camera import SemanticCamera
from metadrive.component.sensors.depth_camera import DepthCamera
import cv2
import gymnasium as gym
import numpy as np
from metadrive.policy.idm_policy import IDMPolicy
from metadrive.obs.observation_base import BaseObservation
from metadrive.obs.image_obs import ImageObservation
from metadrive.obs.state_obs import StateObservation
import os
sensor_size = (84, 60) if os.getenv('TEST_DOC') else (200, 100)
class MyObservation(BaseObservation):
def __init__(self, config):
super(MyObservation, self).__init__(config)
self.rgb = ImageObservation(config, "rgb", config["norm_pixel"])
self.depth = ImageObservation(config, "depth", config["norm_pixel"])
self.semantic = ImageObservation(config, "semantic", config["norm_pixel"])
self.state = StateObservation(config)
@property
def observation_space(self):
os={o: getattr(self, o).observation_space for o in ["rgb", "state", "depth", "semantic"]}
return gym.spaces.Dict(os)
def observe(self, vehicle):
os={o: getattr(self, o).observe() for o in ["rgb", "state", "depth", "semantic"]}
return os
After this, we notify the engine to use this observation with the field agent_observation. Note we don’t need to specify the cfg['vehicle_config']['image_source'], as it is used in ImageStateObservation which is already overwritten with our customized observation class. In addition, you have to request corresponding sensors so the observation class can find these sensors from the engine. Actually, you are allowed to create any number of sensors according to your demand. All available sensors can be found at Sensors. At last, the config should look like:
cfg=dict(agent_policy=IDMPolicy, # drive with IDM policy
agent_observation=MyObservation,
image_observation=True,
sensors={"rgb": (RGBCamera, *sensor_size),
"depth": (DepthCamera, *sensor_size),
"semantic": (SemanticCamera, *sensor_size)},
log_level=50) # turn off log
Once finishing the setup, the following code will launch the simulation and show you the image observations returned by env.step(), which should contain images from three cameras.
from metadrive.utils.doc_utils import generate_gif
from IPython.display import Image
frames = []
env=MetaDriveEnv(cfg)
try:
env.reset()
print("Observation shape: \n", env.observation_space)
for step in range(1 if os.getenv('TEST_DOC') else 1000):
o, r, d, _, _ = env.step([0,1]) # simulation
# visualize image observation
o_1 = o["depth"][..., -1]
o_1 = np.concatenate([o_1, o_1, o_1], axis=-1) # align channel
o_2 = o["rgb"][..., -1]
o_3 = o["semantic"][..., -1]
ret = cv2.hconcat([o_1, o_2, o_3])*255
ret=ret.astype(np.uint8)
frames.append(ret[..., ::-1])
if d:
break
generate_gif(frames if os.getenv('TEST_DOC') else frames[-300:-50]) # only show 250 frames
finally:
env.close()
Observation shape:
Dict('depth': Box(-0.0, 1.0, (100, 200, 1, 3), float32), 'rgb': Box(-0.0, 1.0, (100, 200, 3, 3), float32), 'semantic': Box(-0.0, 1.0, (100, 200, 3, 3), float32), 'state': Box(-0.0, 1.0, (19,), float32))
Image(open("demo.gif", 'rb').read(), width=256*3, height=128)

Customization-MultiView
Usually, you don’t need to create a certain type of image sensor multiple times and maintain many instances in the game engine. Instead, you can create just one sensor but mount it to different positions and poses to collect multiple rendering results. In this way, the rendering can be more efficient.
In the following example, we want 4 RGB cameras to monitor the traffic density of 4 entries of an intersection. In practice, we don’t create any new RGB cameras but use the main RGB camera. In every frame, we move it to 4 target positions to collect data. The result is the same as capturing images with 4 different RGB cameras, which harms the simulation’s performance.
More sensor examples can be found in Sensors.
from metadrive.envs.metadrive_env import MetaDriveEnv
import cv2
import gymnasium as gym
import numpy as np
from metadrive.obs.observation_base import BaseObservation
from metadrive.obs.image_obs import ImageObservation
import os
from metadrive.utils.doc_utils import generate_gif
from IPython.display import Image
sensor_size = (1, 1) if os.getenv('TEST_DOC') else (200, 200)
class MyObservation(BaseObservation):
def __init__(self, config):
super(MyObservation, self).__init__(config)
self.rgb = ImageObservation(config, "main_camera", config["norm_pixel"])
@property
def observation_space(self):
os = {"entry_{}".format(idx): self.rgb.observation_space for idx in range(4)}
os["top_down"] = self.rgb.observation_space
return gym.spaces.Dict(os)
def observe(self, vehicle):
ret = {}
# The first rendered image is the top-down view
ret["top_down"] = self.rgb.observe()
# The camera can be borrowed to render new images with new poses
for idx in range(4):
ret["entry_{}".format(idx)] = self.rgb.observe(self.engine.origin,
position=[70, 8.75, 8],
hpr=[idx * 90, -15, 0])
return ret
env_cfg = dict(agent_observation=MyObservation,
image_observation=True,
window_size=sensor_size,
map="X",
show_terrain=not os.getenv('TEST_DOC'),
traffic_density=0.2,
show_interface=False,
show_fps=False,
traffic_mode="respawn",
log_level=50, # no log message
vehicle_config=dict(image_source="main_camera"))
def reset_sensors(self):
"""
Put the main camera to the center of the intersection at the start of each episode
"""
self.main_camera.stop_track()
self.main_camera.set_bird_view_pos([70, 8.75])
self.main_camera.top_down_camera_height = 50
MetaDriveEnv.reset_sensors = reset_sensors
frames = []
env = MetaDriveEnv(env_cfg)
try:
env.reset()
print("Observation shape: \n", env.observation_space)
for step in range(1 if os.getenv('TEST_DOC') else 500):
o, r, d, _, _ = env.step([0, -1]) # simulation
# visualize image observation
o_1 = o["entry_0"][..., -1]
o_2 = o["entry_1"][..., -1]
o_3 = o["entry_2"][..., -1]
o_4 = o["entry_3"][..., -1]
o_5 = o["top_down"][..., -1]
ret = cv2.hconcat([o_1, o_2, o_3, o_4, o_5]) * 255
ret = ret.astype(np.uint8)
frames.append(ret[::2, ::2, ::-1])
generate_gif(frames if os.getenv('TEST_DOC') else frames[-100:]) # only show -100 frames
finally:
env.close()
Observation shape:
Dict('entry_0': Box(-0.0, 1.0, (200, 200, 3, 3), float32), 'entry_1': Box(-0.0, 1.0, (200, 200, 3, 3), float32), 'entry_2': Box(-0.0, 1.0, (200, 200, 3, 3), float32), 'entry_3': Box(-0.0, 1.0, (200, 200, 3, 3), float32), 'top_down': Box(-0.0, 1.0, (200, 200, 3, 3), float32))
Image(open("demo.gif", 'rb').read(), width=100*5, height=100)

FAQ
Can I use LidarState observation but also render the images at the same time?
Yes! You can stick to the original observation by passing config["agent_observation"]=LidarStateObservation but still maintaining the RGB camera with config["sensors"]=dict(rgb_camera=(RGBCamera, ...)). See this example:
from metadrive.envs.metadrive_env import MetaDriveEnv
from metadrive.obs.state_obs import LidarStateObservation
from metadrive.component.sensors.rgb_camera import RGBCamera
import os
test_doc = os.getenv('TEST_DOC')
sensor_size = (84, 60) if test_doc else (200, 100)
env = MetaDriveEnv(config=dict(
use_render=False,
agent_observation=LidarStateObservation,
image_observation=True,
norm_pixel=False,
sensors=dict(rgb_camera=(RGBCamera, *sensor_size)),
))
obs, info = env.reset()
print("Observation shape: ", obs.shape)
image = env.engine.get_sensor("rgb_camera").perceive(to_float=False)
image = image[..., [2, 1, 0]]
if not test_doc:
import matplotlib.pyplot as plt
plt.imshow(image)
plt.show()
[INFO] Environment: MetaDriveEnv
[INFO] MetaDrive version: 0.4.2.3
[INFO] Sensors: [lidar: Lidar(), side_detector: SideDetector(), lane_line_detector: LaneLineDetector(), rgb_camera: RGBCamera(512, 256)]
[INFO] Render Mode: offscreen
[INFO] Horizon (Max steps per agent): None
[WARNING] You have set norm_pixel = False, which means the observation will be uint8 values in [0, 255]. Please make sure you have parsed them later before feeding them to network! (metadrive_env.py:113)
[INFO] Assets version: 0.4.2.3
[INFO] Known Pipes: glxGraphicsPipe
[INFO] Assets version: 0.4.2.3
[INFO] Known Pipes: glxGraphicsPipe
[WARNING] You are using too large buffer! The height is 256, and width is 512. It may lower the sample efficiency! Consider reducing buffer size or use cuda image by set [image_on_cuda=True]. (base_camera.py:49)
[INFO] Start Scenario Index: 0, Num Scenarios : 1
Observation shape: (259,)