Action and Policy
![]()
This section will discuss how to control the vehicle in MetaDrive with the Policy interface. Before this, let’s have a look at the raw control signal required by vehicles.
Action
To control vehicles in MetaDrive, the input should be a normalized action: \(\mathbf a = [a_1, a_2] \in [-1, 1]^2\). This action is converted into the steering \(u_s\) (degree), acceleration \(u_a\) (hp) and brake signal \(u_b\) (hp) in the following ways:
\(u_s = S_{max} a_1\)
\(u_a = F_{max} \max(0, a_2)\)
\(u_b = -B_{max} \min(0, a_2)\)
wherein \(S_{max}\) (degree) is the maximal steering angle, \(F_{max}\) (hp) is the maximal engine force, and \(B_{max}\) (hp) is the maximal brake force. To increase diversity, the accurate values of these parameters vary across different vehicles but are limited to certain ranges defined by VehicleParameterSpace.
The steering \(u_s\) is applied to two front wheels. In addition, the engine force \(u_a\) and the brake force \(u_b\) are applied to four wheels, as the car in MetaDrive is four-wheel drive (4WD). The concrete implementation is as follows:
from metadrive.component.vehicle.base_vehicle import BaseVehicle
from metadrive.utils.doc_utils import print_source
print_source(BaseVehicle._set_action)
print_source(BaseVehicle._apply_throttle_brake)
def _set_action(self, action):
if action is None:
return
steering = action[0]
self.throttle_brake = action[1]
self.steering = steering
self.system.setSteeringValue(self.steering * self.max_steering, 0)
self.system.setSteeringValue(self.steering * self.max_steering, 1)
self._apply_throttle_brake(action[1])
def _apply_throttle_brake(self, throttle_brake):
max_engine_force = self.config["max_engine_force"]
max_brake_force = self.config["max_brake_force"]
for wheel_index in range(4):
if throttle_brake >= 0:
self.system.setBrake(2.0, wheel_index)
if self.speed_km_h > self.max_speed_km_h:
self.system.applyEngineForce(0.0, wheel_index)
else:
self.system.applyEngineForce(max_engine_force * throttle_brake, wheel_index)
else:
if self.enable_reverse:
self.system.applyEngineForce(max_engine_force * throttle_brake, wheel_index)
self.system.setBrake(0, wheel_index)
else:
DEADZONE = 0.01
# Speed m/s in car's heading:
heading = self.heading
velocity = self.velocity
speed_in_heading = velocity[0] * heading[0] + velocity[1] * heading[1]
if speed_in_heading < DEADZONE:
self.system.applyEngineForce(0.0, wheel_index)
self.system.setBrake(2, wheel_index)
else:
self.system.applyEngineForce(0.0, wheel_index)
self.system.setBrake(abs(throttle_brake) * max_brake_force, wheel_index)
Actually, you can make the car 2WD or 4 wheel steering or even increase its number of wheels by implementing a new vehicle type like BaseVehicle.
The aforementioned _set_action(self, action) function is wrapped by the before_step(self, action) function, which will do additional manipulations like numerical validation. Thus to control a vehicle, just set the action through vehicle.before_step(target_action) before simulating the next step. A minimal example to control a vehicle is as follows. The script first creates a new vehicle in front of the green ego car and sets its action as [0, 0.05] at each step. As a result, it slowly moves forward, while the green ego car stops at the origin as its input action is always [0, 0].
from metadrive.envs.metadrive_env import MetaDriveEnv
from metadrive.component.vehicle.vehicle_type import DefaultVehicle
from metadrive.utils.doc_utils import generate_gif
env=MetaDriveEnv(dict(map="S", traffic_density=0))
frames = []
try:
env.reset()
cfg=env.config["vehicle_config"]
cfg["navigation"]=None # it doesn't need navigation system
v = env.engine.spawn_object(DefaultVehicle,
vehicle_config=cfg,
position=[30,0],
heading=0)
for _ in range(100):
v.before_step([0, 0.5])
env.step([0,0])
frame=env.render(mode="topdown",
window=False,
screen_size=(800, 200),
camera_position=(60, 7))
frames.append(frame)
generate_gif(frames, gif_name="demo.gif")
finally:
env.close()
from IPython.display import Image
Image(open("demo.gif", "rb").read())
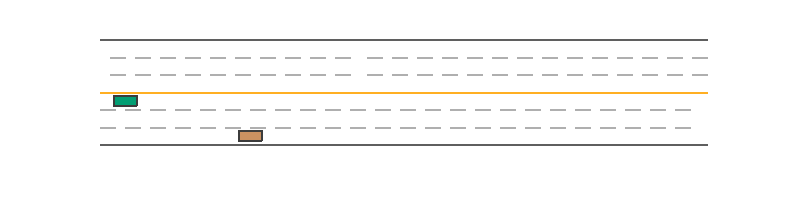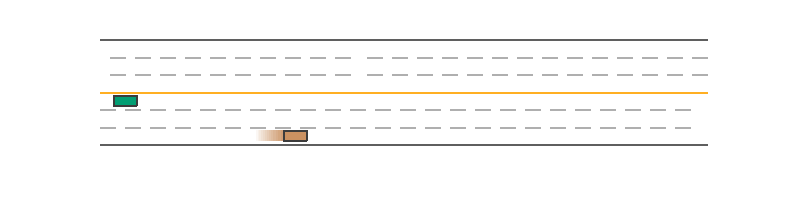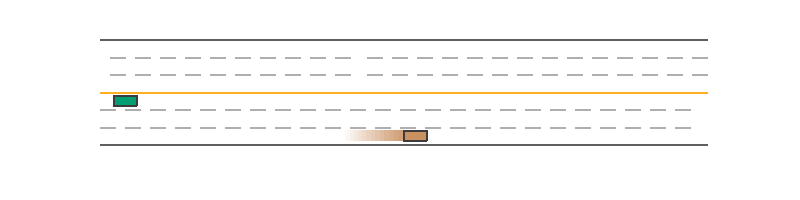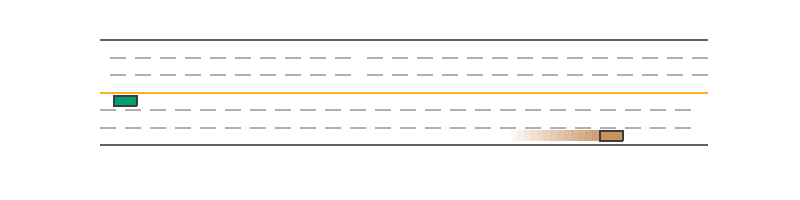
Policy
Generally, we want to control the vehicle in several ways besides providing raw action. For example, we may want to have an intermediate controller to turn the high-level driving commands into the low-level steering, throttle, and brake signals. MetaDrive thus provides such an interface called Policy. The output of any Policy is supposed to be the raw signals taken by vehicle.before_step as input. To make such driving decisions, Policy can access all simulation information such as the map and all other objects as well as the external input signals from env.step. This allows us to make either an intermediate controller or a self-contained self-driving policy like IDMPolicy. Let’s first have a look at the abstract class BasePolicy.
In MetaDrive, every policy should inherit from BasePolicy and reimplement two core methods:
act(self, *args, **kwargs) and def get_input_space(cls). The policy.act() method aims at making driving decisions and thus produces 2-dimension actions for controlling the vehicle. To this end, the policy is allowed to access all information in the driving scene through the simulation engine and the external input from env.step. This external input should be a vector whose shape is defined by policy.get_input_space(). Therefore, the method get_input_space actually defines the action space for the environment and returns arbitrary space of gym.spaces. To elaborate on this, we explain how we design EnvInputPolicy which converts the external input from env.step to continuous signals to control the vehicles.
EnvInputPolicy
This policy allows us to use the vector action accepted by env.step(action) to control the vehicle directly. The vector can represent the 2-dimensional raw continuous action directly or discrete/multi-discrete actions. Thus for an environment using this policy to control the ego vehicle, the action space will be gym.Box, gym.Discrete, or gym.MultiDiscrete.
from metadrive.policy.env_input_policy import EnvInputPolicy
from metadrive.utils.doc_utils import print_source
print_source(EnvInputPolicy.get_input_space)
@classmethod
def get_input_space(cls):
"""
The Input space is a class attribute
"""
engine_global_config = get_global_config()
discrete_action = engine_global_config["discrete_action"]
discrete_steering_dim = engine_global_config["discrete_steering_dim"]
discrete_throttle_dim = engine_global_config["discrete_throttle_dim"]
use_multi_discrete = engine_global_config["use_multi_discrete"]
if not discrete_action:
_input_space = gym.spaces.Box(-1.0, 1.0, shape=(2, ), dtype=np.float32)
else:
if use_multi_discrete:
_input_space = gym.spaces.MultiDiscrete([discrete_steering_dim, discrete_throttle_dim])
else:
_input_space = gym.spaces.Discrete(discrete_steering_dim * discrete_throttle_dim)
return _input_space
According to the definition of get_input_space, one can use these configs to customize the input space of this policy as well as the action space for the environment:
# the type of these config and the default value
discrete_action: bool = False
discrete_steering_dim: int = 5
discrete_throttle_dim: int = 5
use_multi_discrete: bool = False
By default, the action space for the environment is continuous action space bounded by [-1, 1]. Thus the external input, the action, will be used to control the vehicle directly. Also, you can change the action space to a discrete action space by setting discrete_action=True when creating the environment. After that, there will be discrete_steering_dim * discrete_throttle_dim candidate actions that can be chosen by the external policy, i.e. a neural network for controlling the vehicle.
from metadrive.envs.base_env import BaseEnv
env=BaseEnv(dict(discrete_action=True, log_level=50))
num_candidates=env.config["discrete_steering_dim"]*env.config["discrete_throttle_dim"]
assert env.action_space.n == num_candidates
print(env.action_space)
Discrete(25)
The discrete action can also be represented by a multi-discrete vector whose shape is (2,) but each dimension only has discrete_steering_dimand discrete_throttle_dim candidate values respectively.
env=BaseEnv(dict(discrete_action=True, use_multi_discrete=True, log_level=50))
assert env.action_space.shape == (2,)
print(env.action_space)
MultiDiscrete([5 5])
The ExternalInputPolicy converts these discrete input signal into continuous signals automatically via the following function:
print_source(EnvInputPolicy.convert_to_continuous_action)
def convert_to_continuous_action(self, action):
if self.use_multi_discrete:
steering = action[0] * self.steering_unit - 1.0
throttle = action[1] * self.throttle_unit - 1.0
else:
steering = float(action % self.discrete_steering_dim) * self.steering_unit - 1.0
throttle = float(action // self.discrete_steering_dim) * self.throttle_unit - 1.0
return steering, throttle
This function is called in ExternalInputPolicy.act(agent_id) to output the final two dimensional continuous control signal.
print_source(EnvInputPolicy.act)
def act(self, agent_id):
action = self.engine.external_actions[agent_id]
if self.engine.global_config["action_check"]:
# Do action check for external input in EnvInputPolicy
assert self.get_input_space().contains(action), "Input {} is not compatible with action space {}!".format(
action, self.get_input_space()
)
to_process = self.convert_to_continuous_action(action) if self.discrete_action else action
# clip to -1, 1
action = [clip(to_process[i], -1.0, 1.0) for i in range(len(to_process))]
self.action_info["action"] = action
return action
This policy is the default policy of MetaDrive and thus you can control a vehicle by simply changing the action fed into env.step. In the following example, the green ego car keeps doing the left rotation.
from metadrive.envs.metadrive_env import MetaDriveEnv
from metadrive.utils.doc_utils import generate_gif
env=MetaDriveEnv(dict(map="S",
log_level=50,
traffic_density=0))
try:
frames = []
# run several episodes
env.reset()
for step in range(300):
# simulation
_,_,_,_,info = env.step([0.5, 1])
frame = env.render(mode="topdown",
window=False,
screen_size=(800, 200),
camera_position=(60, 15))
frames.append(frame)
generate_gif(frames)
finally:
env.close()
Image(open("demo.gif", "rb").read())
LaneChangePolicy
Unlike the EnvInputPolicy, the LangeChangePolicy accepts high-level commands to determine lane changing and the 3 lane change commands (left, right, keeping) are converted into steering by a PID controller. It is thus an example of intermediate policy connecting high-level driving intention and low-level raw control signals, improving the level of automation.
It is inherited from EnvInputPolicy with use_discrete_action=True and discrete_steering_dim fixed to 3. Thus the shape of its input space is [3, discrete_throttle_dim]. When the first element of action is 0, 1, or 2, the car will perform left lane changing, lane keeping, and right lane changing, respectively. The following example shows an example where the car is performing lane-changing and lane-keeping across 3 lanes. Similar to agent_observation, here we use agent_policy to specify the policy controlling the target vehicle. It overrides the default EnvInputPolicy with LaneChangePolicy.
from metadrive.envs.metadrive_env import MetaDriveEnv
from metadrive.policy.lange_change_policy import LaneChangePolicy
from metadrive.utils.doc_utils import generate_gif
env=MetaDriveEnv(dict(map="C",
discrete_action=True,
use_multi_discrete=True,
agent_policy=LaneChangePolicy,
log_level=50,
traffic_density=0))
frames=[]
try:
# run several episodes
env.reset()
for step in range(300):
# change command
if step<90:
steering = 1
command = "lane keeping"
elif step<100:
steering = 0
command = "right lane changing"
elif step<140:
steering = 1
command = "lane keeping"
elif step<160:
steering = 0
command = "right lane changing"
elif step<200:
steering = 2
command = "left lane changing"
else:
steering = 1
command = "lane keeping"
# simulation
_,_,_,_,info = env.step([steering, 3])
frame= env.render(mode="topdown",
window=False,
text={"command": command},
screen_size=(700, 900),
camera_position=(60,-54))
frames.append(frame)
if info["arrive_dest"]:
break
generate_gif(frames)
finally:
env.close()
Image(open("demo.gif", "rb").read())
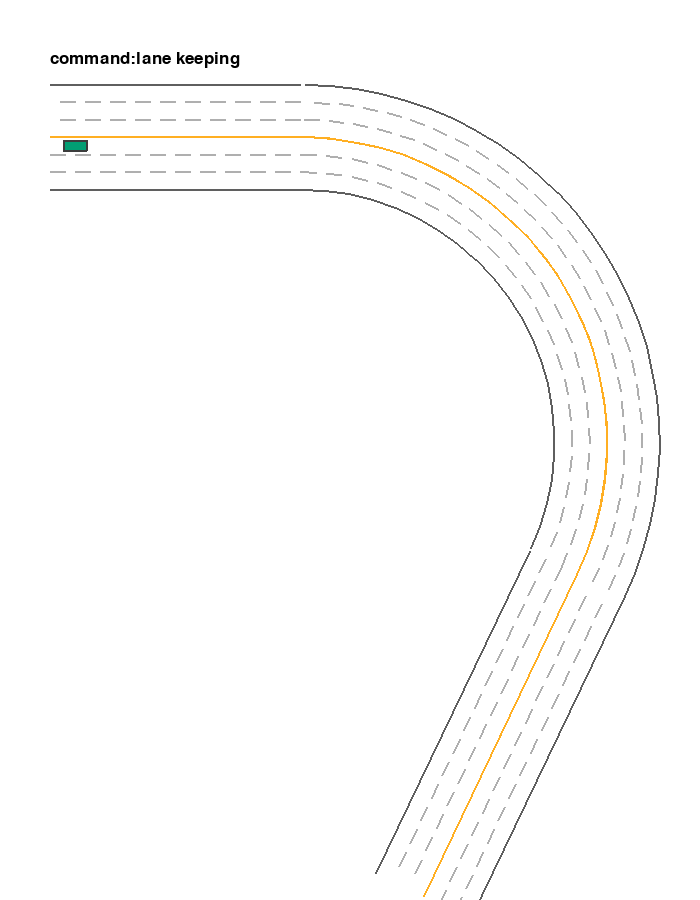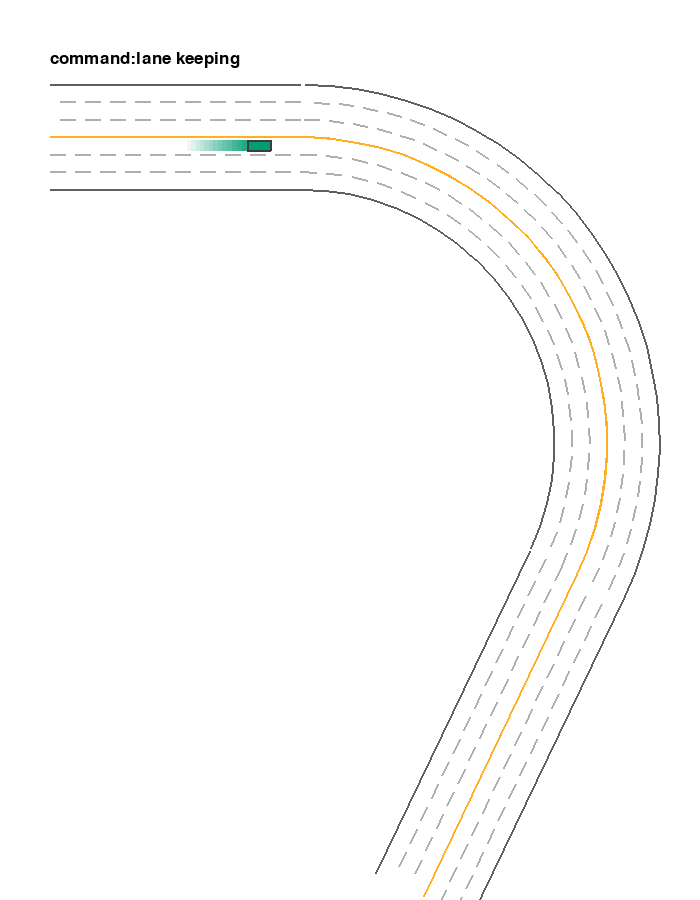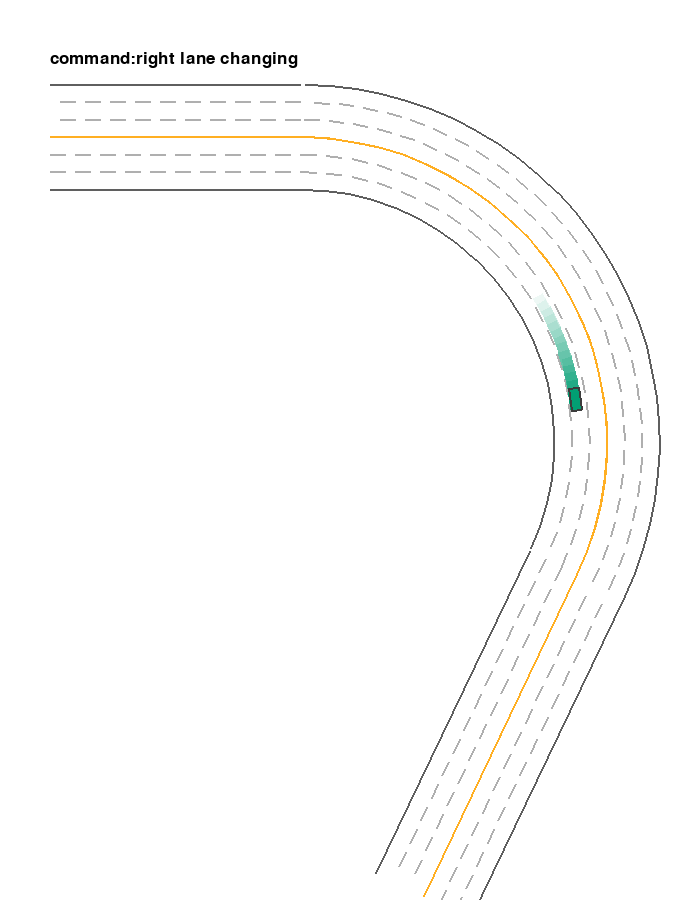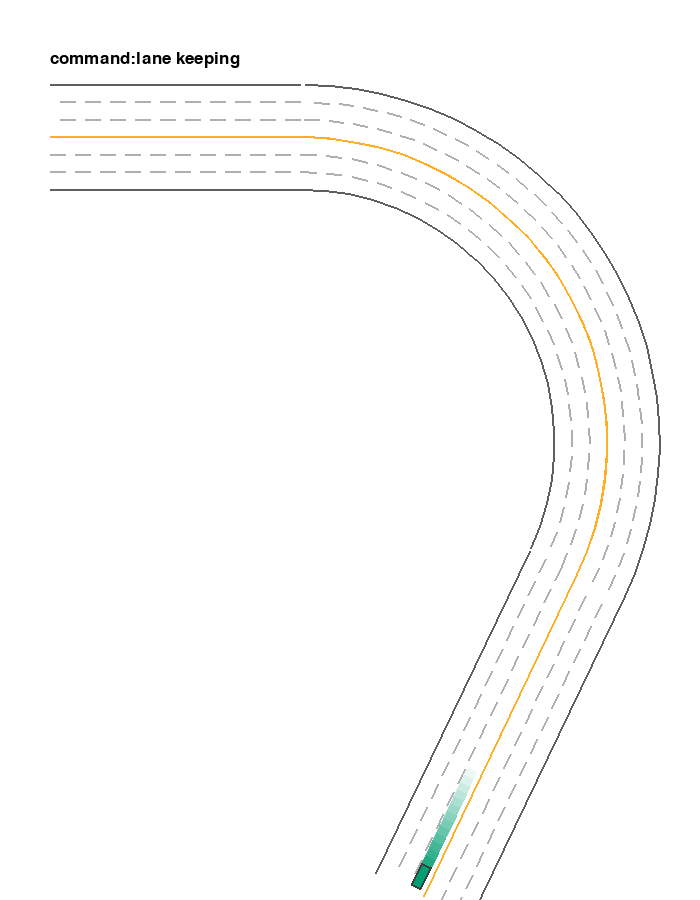
ExtraEnvInputPolicy
Sometimes we want to input more information or control signals to the vehicle control system or the MetaDrive simulator. This can be achieved with ExtraEnvInputPolicy. It allows env.step() to accept more information besides [steering throttle] and thus extra external information can be passed to the simulator. It inherits from EnvInputPolicy and reimplement mainly the get_input_space function.
from metadrive.policy.env_input_policy import ExtraEnvInputPolicy
from metadrive.utils.doc_utils import print_source
print_source(ExtraEnvInputPolicy.get_input_space)
@classmethod
def get_input_space(cls):
"""
Define the input space as a Dict Space
Returns: Dict action space
"""
action_space = super(ExtraEnvInputPolicy, cls).get_input_space()
return gym.spaces.Dict({"action": action_space, "extra": cls.extra_input_space})
The space for extra_input can be set via the class method set_extra_input_space, which takes an gym.spaces.Space as input. After figuring out what kind of extra input you want, we can make such an policy and environment allows more input from env.step(). The following example allows to input a scalar with the 2-dim continuous action to the simulator. The scalar will be stored in the field extra in the action dict. After passing the action dict to the simulator, the scalar is finally stored in policy.extra_input . We turned on the action_check here to check if the action accepted by env.step is contained in env.action_space and policy.input_space.
from metadrive.envs.metadrive_env import MetaDriveEnv
from metadrive.policy.env_input_policy import ExtraEnvInputPolicy
import gymnasium as gym
import random
ExtraEnvInputPolicy.set_extra_input_space(gym.spaces.Discrete(10))
env=MetaDriveEnv(dict(map="S",
agent_policy=ExtraEnvInputPolicy,
action_check=True,
log_level=50))
try:
# run several episodes
env.reset()
for step in range(10):
# simulation
extra = random.randint(0, 9)
action={"action": [0., 0.], "extra": extra}
_,_,_,_,info = env.step(action)
extra_ = env.engine.get_policy(env.agent.id).extra_input
assert extra == extra_
print("Extra info this step is: {}".format(extra))
finally:
env.close()
Extra info this step is: 4
Extra info this step is: 2
Extra info this step is: 8
Extra info this step is: 6
Extra info this step is: 1
Extra info this step is: 5
Extra info this step is: 6
Extra info this step is: 7
Extra info this step is: 1
Extra info this step is: 3
/home/docs/checkouts/readthedocs.org/user_builds/metadrive-simulator/envs/latest/lib/python3.11/site-packages/gymnasium/spaces/box.py:423: UserWarning: WARN: Casting input x to numpy array.
gym.logger.warn("Casting input x to numpy array.")
The space for the extra input can be Box, MultiDiscrete, and Dict. Thus it is very flexible and allows the simulator to interact with external modules.
The EnvInputPolicy, ExtraEnvInputPolicy, and, LaneChangePolicy are similar, as they all need the external input signal accepted by env.step to further vehicle control. However, it is also allowed to have a policy that can make driving decisions without any external action such as a fully autonomous IDM policy. We will introduce this kind of policy in the following content.
ManualControlPolicy
We also allow controlling the agent with a keyboard, steering wheel (Logitech G29), and Xbox. Use config controller to specify which device you are using. The options are keyboard, steering_wheel, xboxController, xboxcontroller, and xbox. To experience the keyboard controller, please try out the single agent example:
# pressing T to switch the driving mode to manual control
python -m metadrive.examples.drive_in_single_agent_env
If you have other controllers, just add one line to the config to enable it like
env=MetaDriveEnv(dict(map="C",
manual_control=True,
controller="xbox") # that's all
Note: if the key manual_control is set to True, the agent_policy will be replaced with the ManualControlPolicy!
IDMPolicy
Given the procedurally generated map, the IDMPolicy in MetaDrive is capable of maintaining the distance with front moving objects and sidestepping static objects automatically. It is the default policy to control the traffic vehicles in MetaDriveEnv. We can use it to control the agent as well. In the following example, all vehicles including the ego car are controlled by the IDMPolicy and they successfully sidestep the traffic ones without collision with each other. The green car also changes from the leftmost lane to the rightmost lane. Note: This policy only works with PGMap and NodeNetwork, which are commonly used by MetaDriveEnv, MARLEnv and SafetyEnv.
from metadrive.envs.metadrive_env import MetaDriveEnv
from metadrive.policy.idm_policy import IDMPolicy
from IPython.display import Image
env=MetaDriveEnv(dict(map="C",
agent_policy=IDMPolicy,
log_level=50,
accident_prob=1.0,
traffic_density=0.2))
try:
# run several episodes
env.reset()
for step in range(300):
# simulation
_,_,_,_,info = env.step([0, 3])
env.render(mode="topdown",
window=False,
screen_record=True,
screen_size=(700, 870),
camera_position=(60,-63)
)
if info["arrive_dest"]:
break
env.top_down_renderer.generate_gif()
finally:
env.close()
Image(open("demo.gif", "rb").read())
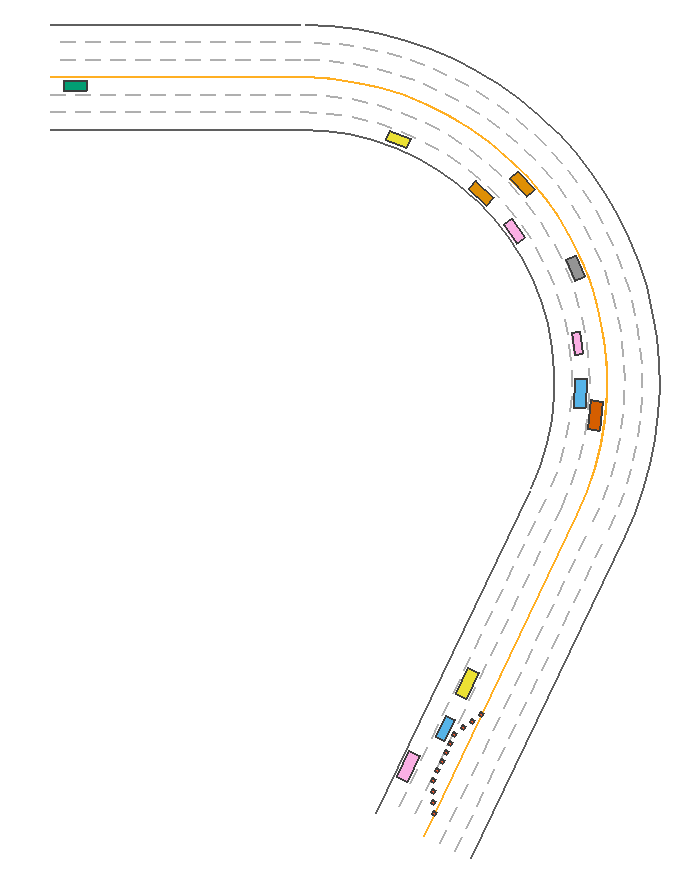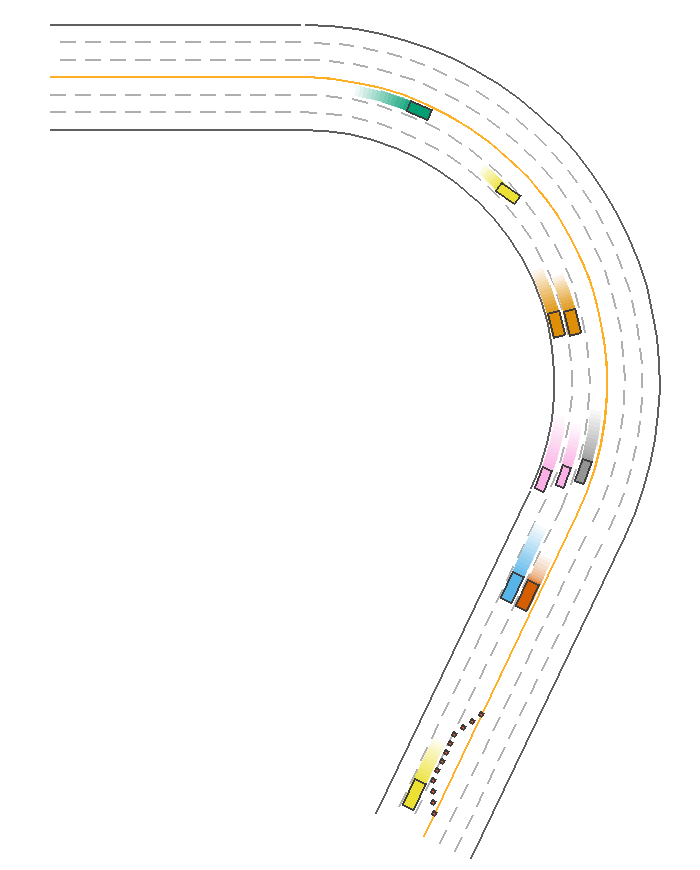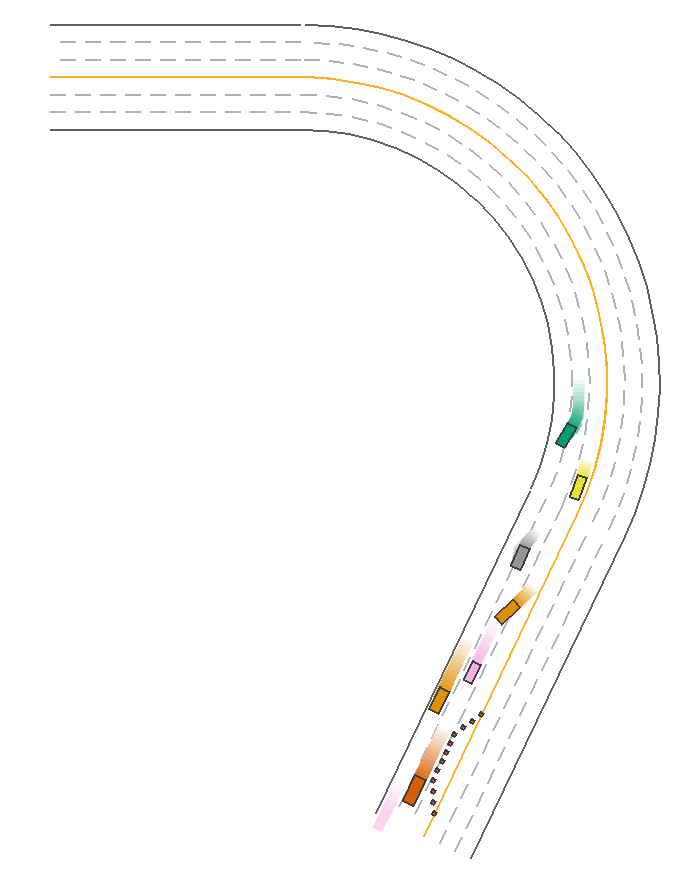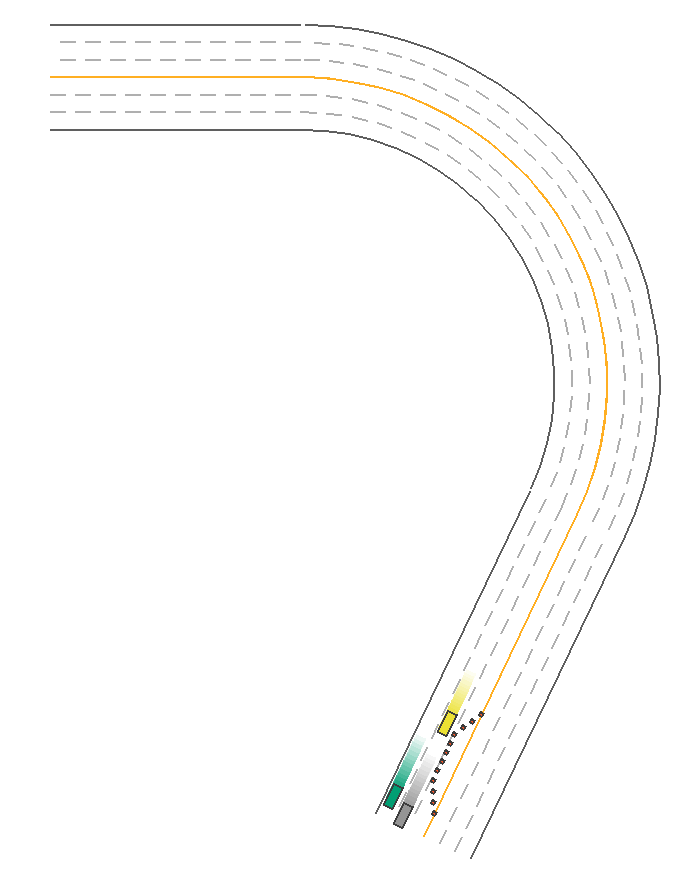
PPOExpertPolicy
The PPO expert policy is a three-layer MLP with tanh activation function. It is well-trained in the MetaDriveEnv and thus can handle most of the driving scenarios. We compress its weights to .npz and thus can load them with numpy. To use it, just specify the agent_policy with ExpertPolicy. Note: This policy only works with PGMap and NodeNetwork, which are commonly used by MetaDriveEnv, MARLEnv, and SafetyEnv.
from metadrive.envs.metadrive_env import MetaDriveEnv
from metadrive.policy.expert_policy import ExpertPolicy
env=MetaDriveEnv(dict(map="C",
agent_policy=ExpertPolicy,
log_level=50,
traffic_density=0.2))
try:
# run several episodes
env.reset()
for step in range(300):
# simulation
_,_,_,_,info = env.step([0, 3])
env.render(mode="topdown",
window=False,
screen_record=True,
screen_size=(700, 870),
camera_position=(60,-63)
)
if info["arrive_dest"]:
break
env.top_down_renderer.generate_gif()
finally:
env.close()
Image(open("demo.gif", "rb").read())
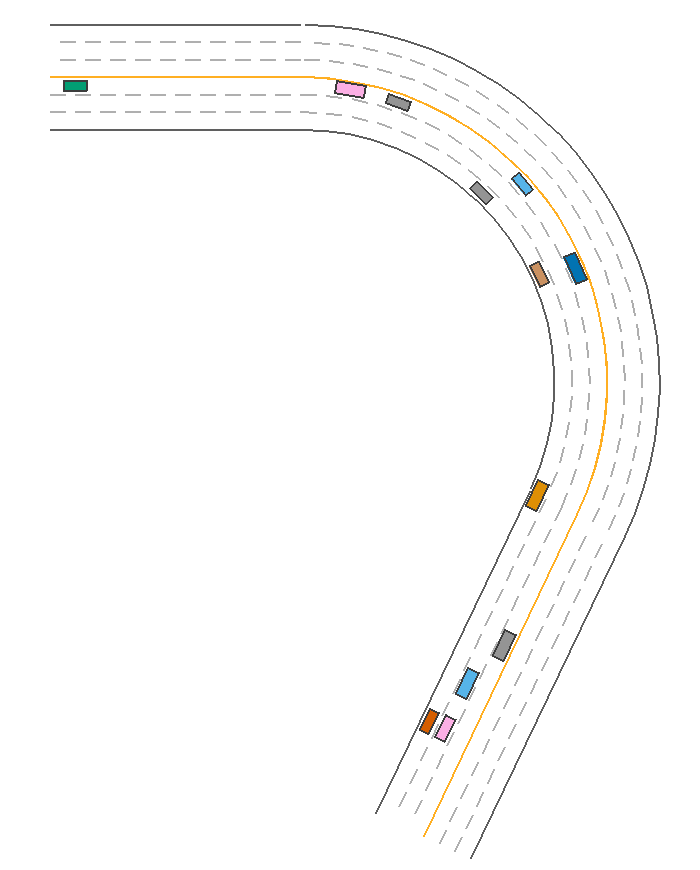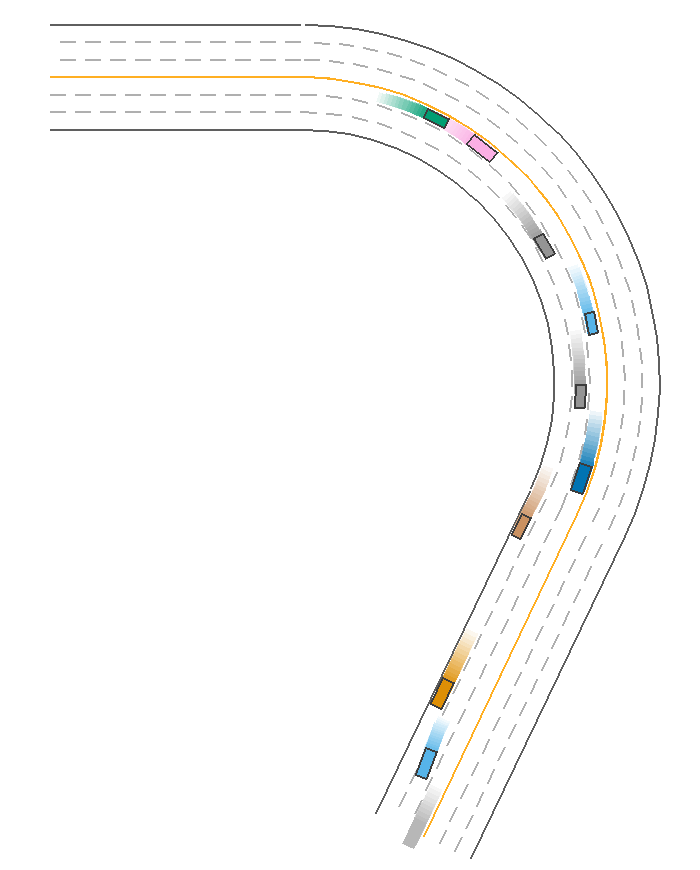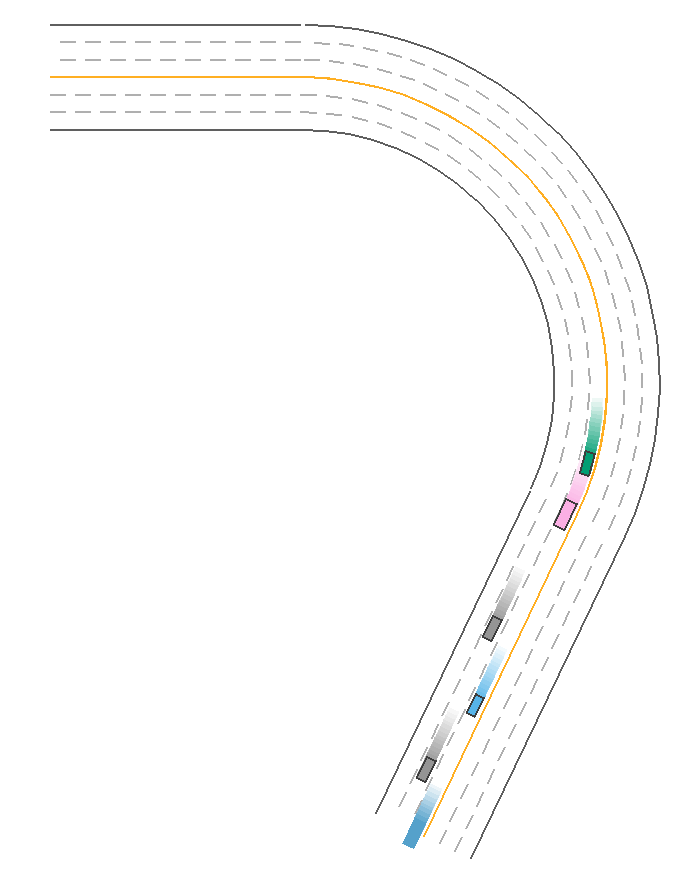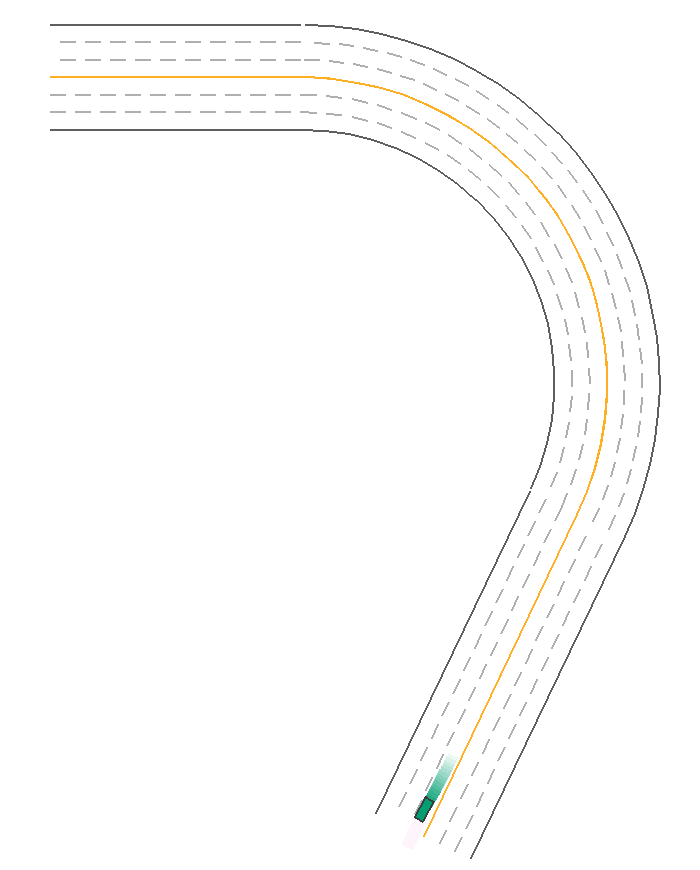
ReplayPolicy
Usually, we use ScenarioNet to convert scenarios collected by Waymo, nuScenes, nuPlan, and Argoverse to internal Scenario Description and rebuild the scenarios in MetaDrive. Thus this policy is used to load and replay the recorded traffic trajectories for these real-world scenarios. There are two replay policies for replaying the trajectories of ego car and traffic participants, respectively:
ReplayEgoCarPolicy
ReplayTrafficParticipantPolicy
The traffic vehicles in ScenarioEnv use the ReplayTrafficParticipantPolicy by default. By specifying the ReplayEgoCarPolicy to the ego car, we can rebuild the whole recorded scenario. The following example reconstructs and shows a nuScenes scenario.
from metadrive.engine.asset_loader import AssetLoader
from metadrive.envs.scenario_env import ScenarioEnv
from metadrive.policy.replay_policy import ReplayEgoCarPolicy
env = ScenarioEnv({
"data_directory": AssetLoader.file_path("nuscenes", unix_style=False),
"agent_policy": ReplayEgoCarPolicy,
"log_level": 50})
try:
env.reset(seed=0)
for t in range(10000):
o, r, tm, tc, info = env.step([0, 0])
env.render(mode="top_down",
window=False,
screen_record=True,
screen_size=(700,700))
if info["replay_done"]:
break
env.top_down_renderer.generate_gif()
finally:
env.close()
Image(open("demo.gif", "rb").read())
TrajectoryIDMPolicy
Sometimes we want the replayed traffic vehicles to be reactive, as the behavior of the ego car may change and be different from the logged one. For example, if the ego car we are controlling drives slower and has a lag with the recorded positions, a rear-end collision will happen between the ego car and the traffic vehicle behind it, which is unreasonable. Thus we introduce a TrajectoryIDMPolicy which allows the traffic vehicles to drive along the logged trajectories but control its speed according to the IDM policy. As a result, it can perform emergency brakes and maintain the distance from the car in front of it automatically.
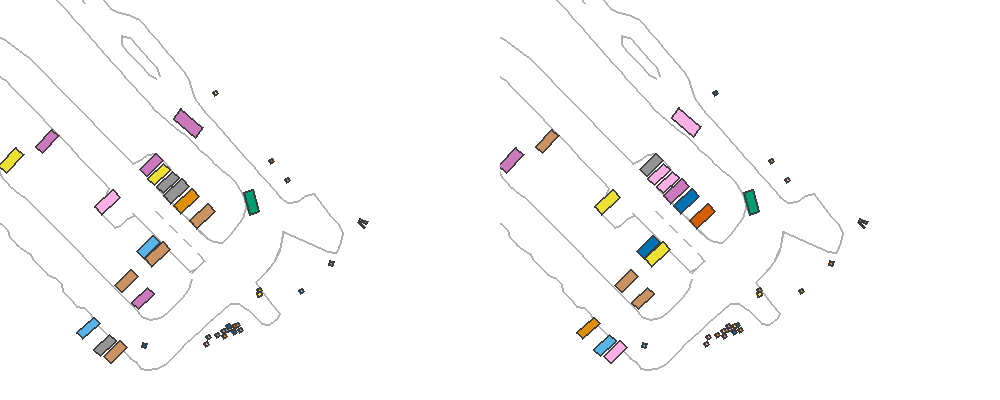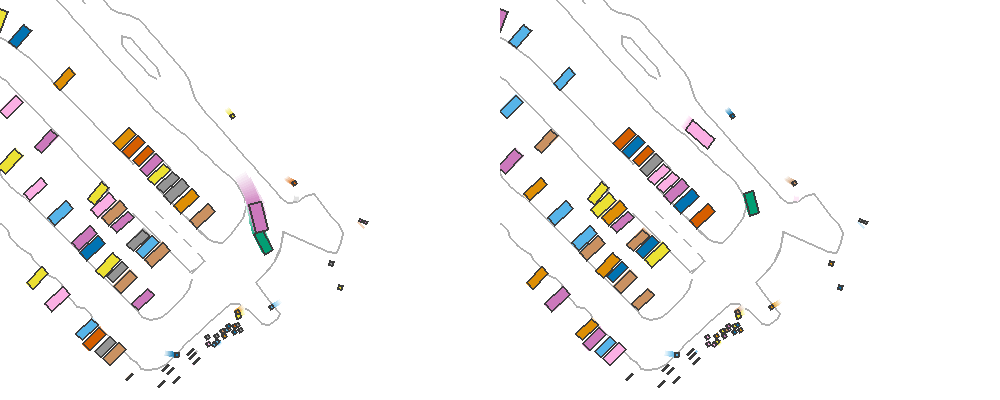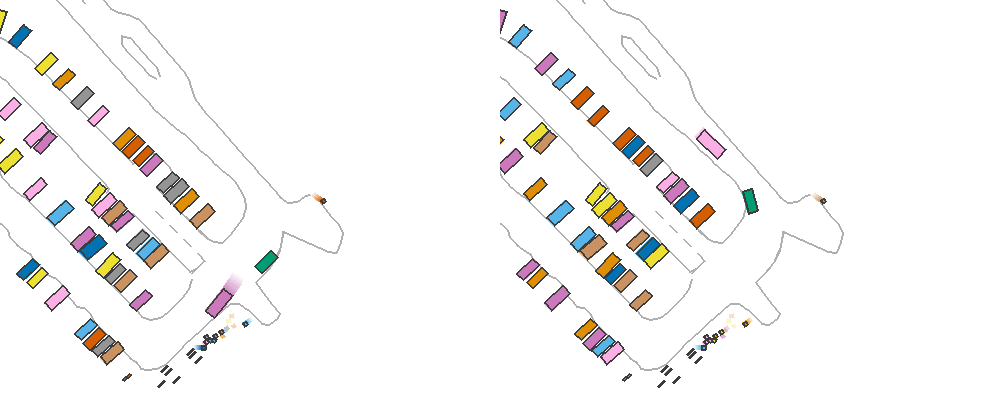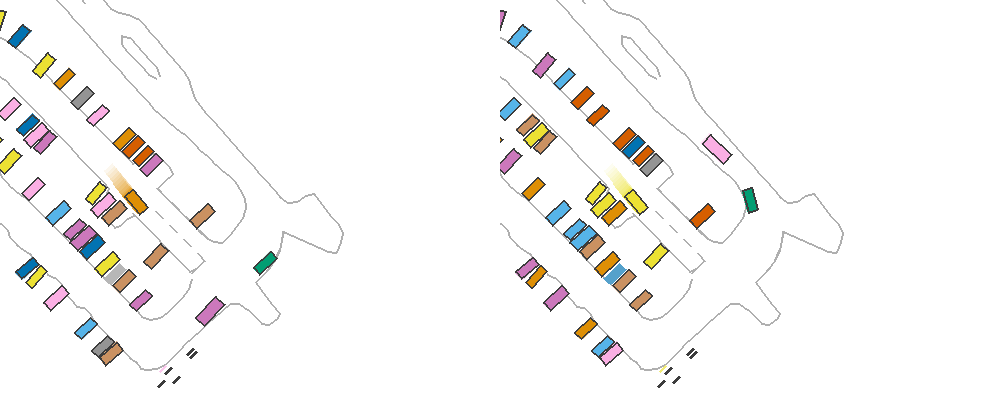
By setting reactive_traffic=True in ScenarioEnv, this policy will be assigned to traffic participants automatically. The following example demonstrates the benefits of having reactive traffic vehicles. In this example, the ego car performs emergency brake rather than following the logged trajectory. The left figure shows results of solely replaying the trajectory of the traffic vehicles, while the left figure shows replaying with IDM policy where the rear vehicle stops and avoids unreasonable rear-end collision.
import numpy as np
from metadrive.engine.asset_loader import AssetLoader
from metadrive.policy.replay_policy import ReplayEgoCarPolicy
from metadrive.envs.scenario_env import ScenarioEnv
from metadrive.utils.doc_utils import generate_gif
import cv2
from IPython.display import Image
nuscenes_data = AssetLoader.file_path(AssetLoader.asset_path, "nuscenes", unix_style=False)
def run_real_env(reactive):
env = ScenarioEnv(
{
"reactive_traffic": reactive,
"data_directory": nuscenes_data,
"start_scenario_index":6, # use scenario #6
"num_scenarios": 1,
"crash_vehicle_done": True,
"log_level": 50,
}
)
try:
o, _ = env.reset(seed=6) # start simulation for senario #6
for i in range(1, 150):
o, r, tm, tc, info = env.step([.0, -1])
env.render(mode="top_down",
window=False,
screen_record=True,
camera_position=(0,0),
screen_size=(500, 400))
frames=env.top_down_renderer.screen_frames
finally:
env.close()
return frames
# visualization
f_1=run_real_env(False)
f_2=run_real_env(True)
frames = []
for i in range(len(f_1)):
frames.append(cv2.hconcat([f_1[i], f_2[i]]))
generate_gif(frames)
Image(open("demo.gif", 'rb').read())
Customization
To make a new policy suiting your need, just create a subclass of BasePolicy and override mainly the function def act(). If this policy will be assigned to an agent, it has to have a correctly defined get_input_space, which will be used to create env.action_space.
The following example shows how to create a policy always executing a left-turning command.
from metadrive.policy.base_policy import BasePolicy
from metadrive.envs import MetaDriveEnv
from IPython.display import clear_output, Image
class LeftTurningPolicy(BasePolicy):
def act(self, *args, **kwargs):
# Always turn left
return [0.4, 0.4]
env = MetaDriveEnv(dict(agent_policy=LeftTurningPolicy,
map="S"))
try:
env.reset()
for _ in range(220):
env.step([-1, -1]) # it doesn't take effect
env.render(mode="topdown",
window=False,
screen_size=(200, 250),
camera_position=(0, 20),
screen_record=True)
env.top_down_renderer.generate_gif()
finally:
env.close()
clear_output()
Image(open("demo.gif", 'rb').read())
